First Time Right — 一次流片成功
芯片流片后经板级测试,各项功能全部正常。在真实硬件平台上成功验证了向量矩阵运算指令,功能指标达到预期设计目标,实现"一次成功"的流片成果。
本项目基于 TSMC 65nm 工艺节点,设计并实现了一款低功耗存内计算(Computing-in-Memory, CIM)芯片。存内计算是一种突破传统冯·诺依曼瓶颈的新型计算范式,通过在存储器内部直接完成计算操作,大幅减少了数据在处理器与存储器之间搬运所带来的功耗与延迟。
核心存储阵列涵盖多种存储单元架构,包括 6T SRAM、双端口 SRAM 及 4T eDRAM,以适配不同计算场景对速度、面积与功耗的差异化需求。芯片采用存算一体架构,支持向量矩阵乘法(VMM)的高效硬件加速。
整个 CIM 系统由以下核心模块构成:
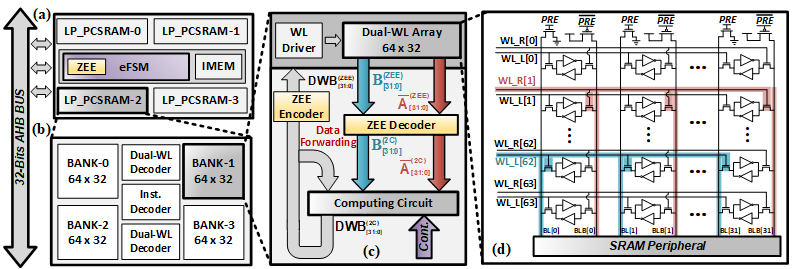
▲ Tiny-vp CIM 存储阵列结构图

▲ TSMC 65nm CIM 芯片 — Wire Bonding 封装实物图

▲ TSMC 65nm CIM 芯片 — 测试板实物图
芯片流片后经板级测试,各项功能全部正常。在真实硬件平台上成功验证了向量矩阵运算指令,功能指标达到预期设计目标,实现"一次成功"的流片成果。